리액티브 스트림(Reactive Streams)은 JVM 환경에서 리액티브 프로그래밍의 표준 API 사양으로 비동기 데이터 스트림과 논블로킹 백프레셔(Back-Pressure)에 대한 사양을 제공합니다. 리액티브 스트림 이전의 비동기식 애플리케이션에서는 멀티 CPU 코어를 제대로 활용하기 위해 복잡한 병렬 처리 코드가 필요했습니다. 또한 처리할 데이터가 무한정 많아져서 시스템의 한계를 넘어서는 경우 애플리케이션은 병목 현상(bottleneck)이 발생하거나 심각한 경우 애플리케이션이 정지되는 경우도 발생하게 됩니다. 리액티브 스트림은 이러한 문제를 해결하기 위해 탄생했습니다.
리액티브 스트림 사양이 만들어지기 전에는 표준화된 사양이 없었으므로 라이브러리마다 각자의 방식으로 구현을 해야 했습니다. 이런 이유로 2013년부터 리액티브 스트림이라는 이름으로 Netflix, Pivotal, Lightbend, Red Hat과 같은 유명 회사들이 공동으로 표준화 작업에 참여하고 있습니다. 2015년 리액티브 스트림 사양이 최초 릴리즈 된 후 현재 1.0.3까지 릴리즈 되었습니다. 몇년 사이 리액티브 스트림 표준 사양을 지원하는 라이브러리들이 많이 발표됬고 JDK9에는 Flow라는 이름으로 리액티브 스트림 구현이 추가되었습니다.
리액티브 스트림의 목표는 개발자들로 하여금 용어(Glossary)를 통일하고 라이브러리들이 리액티브 스트림 사양을 준수하여 일관성 있는 구현을 따르도록 만드는 것입니다.
리액티브 스트림의 다양한 구현체들
리액티브 스트림은 TCK(Technology Compatibility Kit)를 지원합니다. 기술 호환성 키트라고 불리는 TCK는 라이브러리가 정해진 사양에 맞게 구현되었는지 보장하기 위해 만들어진 테스트 도구입니다. 자바 진영에서 Java SE 표준을 따른 JDK(Java Development Kit)인지 검증하기 위해 TCK를 사용합니다. 예를 들어 오픈 소스 JDK인 AdoptOpenJDK, Amazon Corretto 등이 TCK를 사용해 사양을 검증했습니다. TCK 테스트를 통과했다면 라이브러리의 구현이 사양에 맞게 구현되었다는 의미이므로 안정성이 중요한 사용자 입장에선 믿고 사용할 수 있게 됩니다.
리액티브 스트림도 이와 마찬가지로 리액티브 스트림 사양을 구현한 라이브러리는 TCK에 정의된 규칙을 통과해야만 검증된 라이브러리임을 확인할 수 있도록 하였습니다. 또한 리액티브 스트림은 라이브러리가 표준 사양을 준수하는 TCK 테스트를 통과하기만 한다면 사양에 포함되지 않은 라이브러리만의 추가 기능도 자유롭게 구현할 수 있도록 하였습니다.
리액티브 스트림을 표준 사양을 채택한 대표적인 라이브러리들
Project Reactor
RxJava
JDK9 Flow
Akka Streams
Vert.x
리액티브 스트림 사양
리액티브 스트림 사양(specification)은 핵심 인터페이스와 프로토콜로 구성됩니다. 먼저 리액티브 스트림에서 제공하는 핵심 인터페이스를 확인해보겠습니다.
그림 1.7 리액티브 스트림 인터페이스
표 1.5 리액티브 스트림 인터페이스
인터페이스 명
설명
Publisher
데이터를 생성하고 구독자에게 통지
Subscriber
데이터를 구독하고 통지 받은 데이터를 처리
Subscription
Publisher, Subscriber간의 데이터를 교환하도록 연결하는 역할을 하며 전달받을 데이터의 개수와 구독을 해지할 수 있다
Processor
Publisher, Subscriber을 모두 상속받은 인터페이스
핵심 인터페이스에 대해 요약하면 발행자(Publisher)는 데이터를 생성하고 구독자(Subscriber)에게 데이터를 통지하고 구독자는 자신이 처리할 수 있는 만큼의 데이터를 요청하고 처리합니다. 이때 발행자가 제공할 수 있는 데이터의 양은 무한(unbounded) 하고 순차적(sequential) 처리를 보장합니다.
서브스크립션(Subscription)은 발행자와 구독자를 연결 하는 매개체이며 구독자가 데이터를 요청하거나 구독을 해지하는 등 데이터 조절에 관련된 역할을 담당합니다. 프로세서(Processor)는 발행자와 구독자의 기능을 모두 포함하는 인터페이스이며 데이터를 가공하는 중간 단계에서 사용합니다.
간단히 리액티브 스트림의 핵심 인터페이스가 하는 일에 대해 알아봤으니 실제 자바로 작성된 코드를 보면서 리액티브 스트림에서 필수적인 사양도 같이 알아보겠습니다.
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
발행자는 subscribe에서 구독자인 Subscriber를 등록하고 구독자에게 데이터를 순차적으로 통지합니다. 이때 발행자는 구독자가 요청한 만큼의 데이터를 통지합니다. 또한 발행자는 구독자가 요청한 데이터를 처리하는 중에 에러가 발생하거나 또는 완료 처리 신호가 발생하게 되면 더 이상 데이터를 통지하지 않습니다. 그리고 subscribe에서 전달받은 구독자가 null이라면 즉시 java.lang.NullPointException을 발생시킵니다.
구독자 인터페이스에는 4가지의 추상 메서드가 정의되있습니다.
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
구독자의 메서드들은 리액티브 스트림에서 구독자와 발행자간의 데이터 전달에 사용하는 규약(Protocol)이라고 설명하고 있습니다.
표 1.6 서브스크립션에 정의된 추상 메서드
메서드 명
설명
onSubscribe
구독시 최초에 한번만 호출
onNext
구독자가 요구하는 데이터의 수 만큼 호출 (최대 java.lang.Long.MAX_VALUE)
onError
에러 또는 더이상 처리할 수 없는 경우
onComplete
모든 처리가 정상적으로 완료된 경우
이때 각 메서드의 호출을 시그널(Signal)이라고 부릅니다. 각 시그널은 호출되는 순서가 다릅니다. onSubscribe는 최초 구독에 대한 초기화를 담당합니다. 구독 시 최초 한 번만 호출되기 때문에 onSubscribe 내부에서 초기화 로직을 구현할 수 있습니다.
onNext는 발행자로부터 통지받을 데이터가 있는 경우 구독자가 요청하는 만큼 계속 호출됩니다. 이때 발행자가 통지하는 데이터의 수는 구독자가 요구하는 수와 같거나 적어야 합니다. 이런 사양이 있는 이유는 발행자가 너무 많은 데이터를 통지해서 구독자가 처리할 수 있는 양보다 많아지면 시스템에 문제가 발생할 수 있기 때문에 적절하게 처리량을 조절하기 위함입니다.
반대로 구독자가 onNext에서 데이터를 처리하는 데 오래 걸린다면 발행자도 영향을 받을 수 있습니다. 이때는 발행자와 구독자를 분리하여 비동기적으로 처리해야 합니다.
발행자 측에서 처리 중 에러가 발생하면 onError를 구독자에게통지합니다. onError 시그널이 발생하면 더 이상 데이터를 통지하지 않습니다. 구독자는 onError 시그널을 받으면 이에 대한 에러 처리를 할 수 있습니다. onComplete는 모든 데이터를 통지한 시점에 마지막에 호출되어 데이터 통지가 성공적으로 완료되었음을 통지합니다. onError와 onComplete는 반드시 둘중 하나만 호출되야하며 이후에는 어떠한 시그널도 발생해선 안됩니다. 만약 onError가 발생하고 onComplete가 발생한다면 에러가 발생한 것인지 정상적으로 완료되었는지 판단할 수 없기 때문입니다.
public interface Subscription {
public void request(long n);
public void cancel();
}
구독자가 발행자에게 통지받을 데이터의 수를 요청할 때 서브스크립션의 request(long n)를 사용하는데 onSubscribe에서 최초 통지받을 개수를 요청하기 위해 사용하고 그다음엔 onNext에서 데이터 처리 후 다음에 통지받을 데이터 개수를 재요청합니다. 만약 request(long n)에 0보다 작거나 같은 수가 전달된 경우 IllegalArgumentException가 발생합니다. cancel은 구독을 취소하기 위해 사용합니다. 구독을 취소하면 발행자와 구독자의 연결이 끊어지므로 발행자는 더 이상 데이터를 통지하지 않습니다. cancel이 호출되면 비동기적으로 시그널이 발생하여 구독 취소 여부가 지연되어 처리될 수 있습니다.
그림 1.8 리액티브 스트림에서 발행자 구독자 간의 데이터 처리 흐름
마지막으로 소개할 프로세서는 발행자와 구독자를 모두 상속받는 인터페이스 이며 자신만의 추상 메서드는 존재하지 않습니다.
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}
프로세서는 일반적으로 데이터의 가공 단계에서 사용되어 발행자와 구독자의 모든 사양을 따릅니다.
동기(Synchronous)방식의 프로그램에서 작업의 실행 흐름은 순차적으로 동작합니다. 순차적으로 동작하는 프로그램은 코드를 파악하기 쉽고 결과를 예측하기 쉽다는 장점이 있지만 특정 작업을 실행하는 동안에는 다른 작업을 할 수 없다는 단점이 있습니다. 이에 반해 비동기 처리 방식은 현재 실행 중인 작업이 끝나는 것을 기다리지 않고 다른 작업을 할 수 있습니다. 이러한 특징을 가진 비동기 프로그래밍은 서버, 모바일, 데스크톱 등 어떤 환경의 애플리케이션을 개발하더라도 유용하게 사용됩니다.
예를 들어 트위터나 페이스북 같은 SNS 서비스를 개발한다면 외부의 다양한 데이터 소스 또는 원격 서비스로부터 데이터를 가져온 뒤 적절하게 가공하고 하나로 합쳐서 클라이언트에게 응답하게 되는데 이런 경우 비동기 프로그래밍이 유용할 수 있습니다. 또 UI 애플리케이션의 경우 특정 이벤트에 반응하는 동작을 구현해야 하는데 이럴 때 필수적으로 비동기 프로그래밍을 사용하게 됩니다. 대부분의 프로그래밍 언어들은 각 언어의 철학에 맞는 다양한 비동기 처리 방법들을 지원합니다. 비동기 처리 방법에는 대표적으로 스레드(Thread), 콜백(Callback), 프로미스(Promise), 퓨처(Future), 코루틴(Coroutine) 등이 있고 각각의 방법들은 장점과 단점이 존재하고 언어와 라이브러리에 따라 지원되지 않는 경우도 있습니다. 리액티브 프로그래밍에 대한 학습에 앞서 기본적인 비동기 프로그래밍 지식은 필수입니다. 리액티브 프로그래밍에서 비동기 처리를 적용하면 콜백 헬에서 벗어날 수 있으며 퓨처를 사용했을때 성능 하락을 유발하는 블로킹 문제를 논 블로킹 형태로 쉽게 변경할 수 있습니다. 이번 절에서는 비동기 프로그래밍에 대한 기본적인 지식과 문제점에 대해 알아보겠습니다.
스레드
스레드는 서버 프로그래밍에서 가장 기본이 되는 비동기 처리 방식입니다. 하나의 프로세스(Process)에는 최소한 하나 이상의 스레드가 존재하고 프로세스 내의 스레드들은 동일한 메모리를 공유합니다. 일반적으로 하나의 프로세스에서 스레드가 1개인 경우 싱글 스레드(Single Thread)라고 부르고 하나 이상 존재하는 경우 멀티 스레드(Multi Thread)라고 부릅니다. 멀티 스레드를 사용하면 애플리케이션에서 여러 개의 작업을 동시에 할 수 있게 됩니다.
이번에는 스레드 자신의 이름을 출력하는 기능을 가진 5개의 스레드를 사용하는 간단한 멀티 스레드 예제를 만들어보겠습니다.
예제 1.3 현재 스레드의 이름을 반환하는 예제
package thread
class PrintRunnable : Runnable {
override fun run() {
println("current-thread-name : ${Thread.currentThread().name}")
}
}
예제 1.3의 PrintRunnable은 java.lang 패키지의 Runnable 인터페이스를 구현하는 클래스입니다. 러너블(Runnable) 인터페이스를 사용하려면 run 함수를 필수로 구현해야합니다. run 내부에는 스레드 자신의 이름을 출력하도록 하였습니다. 그다음 메인 함수에서 5번 반복문을 수행하면서 PrintRunnable을 감싼 스레드를 생성하고 스레드를 동작시킵니다. 마지막엔 마찬가지로 현재 동작 중인 스레드 이름을 출력하는 print 함수를 호출합니다.
package thread
fun main(args: Array<String>) {
for (i in 0..5) {
val thread = Thread(PrintRunnable())
thread.start()
}
println("current-thread-name : ${Thread.currentThread().name}")
}
--------------------
출력 결과)
--------------------
current-thread-name : Thread-0
current-thread-name : Thread-3
current-thread-name : Thread-2
current-thread-name : Thread-1
current-thread-name : main
current-thread-name : Thread-4
current-thread-name : Thread-5
예제 1.4에서 출력된 결과는 예제를 실행할 때마다 달라지는 걸 확인할 수 있습니다. 만약 멀티 스레드를 사용하지 않고 예제를 출력하면 current-thread-name은 모두 main으로 출력됩니다. main은 메인 스레드로 불리며 JVM 기반의 언어에서 가장 기본이 되는 스레드를 말합니다.
앞서 멀티 스레드 스레드는 생성한 순서대로 동작하지 않고 무작위로 동작하는걸 확인했습니다. 다수의 스레드를 사용하면 스레드가 전환되면서 컨텍스트 스위칭(Context Switching)이 발생합니다.
그림 1.3 멀티 스레드의 동작 방식
멀티 스레드를 사용하면 스케쥴링 알고리즘에 의해 컨텍스트 스위칭이 일어나면서 특정 스레드가 작업을 실행하다가 다른 스레드로 전환되면서 새로운 작업을 하고 다시 원래 스레드로 돌아와서 일시 중지했던 작업을 이어서 완료합니다. 멀티 스레드를 사용하면 스레드마다 작업을 나눠서 처리할 수 있기 때문에 여러 개의 작업을 효율적으로 처리할 수 있습니다. 또한 스레드는 프로세스보다 가볍고 하나의 프로세스 내에서 여러 개의 스레드를 생성하면 메모리 자원을 공유할 수 있다는 장점을 가지고 있습니다.
하지만 스레드가 무한정 많아지면 생성된 스레드로 인해 메모리 사용량이 높아지게 되어 OutOfMemoryError가 발생할 수 있고 동시 처리량이 높아야 하는 시스템의 경우 스레드를 생성하면서 발생하는 대기 시간 때문에 클라이언트에게 빠른 응답을 줄 수 없게 됩니다. 이러한 문제를 극복하려면 스레드 풀(Thread Pool)을 사용해야 합니다. 스레드 풀을 사용하면 애플리케이션 내에서 사용할 총 스레드 수를 제한할 수 있고 이미 생성된 스레드를 재사용하므로 클라이언트는 빠른 응답을 받을 수 있습니다.
스레드 풀은 직접 만드는 것보다 검증된 라이브러리를 사용하는 것이 좋습니다. 그러므로 java.util.concurrent 패키지가 제공하는 ExecutorService를 사용하면 쉽고 안정적으로 스레드 풀을 사용할 수 있습니다.
예제 1.5 ExecutorService를 사용해 스레드 실행하기
package thread
import java.util.concurrent.ExecutorService
import java.util.concurrent.Executors
fun main(args: Array<String>) {
val pool: ExecutorService = Executors.newFixedThreadPool(5)
try {
for (i in 0..5) {
pool.execute(PrintRunnable())
}
} catch (e: Exception) {
pool.shutdown()
}
println("current-thread-name : ${Thread.currentThread().name}")
}
--------------------
출력 결과)
--------------------
current-thread-name : pool-1-thread-1
current-thread-name : pool-1-thread-2
current-thread-name : pool-1-thread-3
current-thread-name : pool-1-thread-4
current-thread-name : main
current-thread-name : pool-1-thread-5
current-thread-name : pool-1-thread-5
Executors.newFixedThreadPool을 사용하면 주어진 수만큼의 스레드를 생성하고 유지합니다. 즉 5로 값을 설정하면 5개의 스레드는 항상 유지되는 걸 보장합니다.
pool.execute는 러너블 인터페이스를 받아서 단순히 실행합니다. execute는 별도의 반환형이 없기 때문에 작업의 결과나 상태를 알 수 없습니다.
예제 1.5에서 출력된 결과를 보면 스레드 이름에 pool-1로 시작하는 것을 확인할 수 있습니다. 이름에서 유추할 수 있듯이 pool-1로 시작되는 스레드는 스레드 풀에서 관리되는 스레드라는 것 을 알 수 있습니다. 또 한 가지 스레드 풀을 사용하면서 다른 점은 마지막 두 개 작업은 pool-1-thread-5라는 동일한 스레드에서 처리되었습니다. 그러므로 스레드를 새로 생성한 게 아니라 스레드 풀에 이미 생성된 스레드를 재사용했다는 것을 알 수 있습니다.
퓨처
퓨처(Future)는 비동기 작업에 대한 결과를 얻고 싶은 경우 사용되는 인터페이스입니다. 퓨처를 사용하면 스레드를 직접 사용하는 것보다 직관적이기 때문에 이해하기 쉽고 모든 작업이 끝나면 작업에 대한 결과를 얻어서 별도의 처리를 할 수 있게 됩니다. 예를 들어 수행 시간이 오래 걸리는 작업이나 작업에 대한 결과를 기다리면서 다른 작업을 병행해서 수행하고 싶은 경우에 유용합니다.퓨처를 사용해 처리 결과를 얻기 위해선 콜러블(Callable)을 사용해야 합니다. 앞선 예제에서 사용한 러너블은 결과 반환을 지원하지 않으므로 콜러블을 사용해 완료된 결과를 퓨처에 넘길 수 있습니다. 다음 예제는 퓨처를 사용해 비동기적으로 계산하고 결과를 리턴합니다.
예제 1.6 정해진 시간만큼 대기한 후 계산하는 계산기
package future
object Calculator {
fun sum(a: Int, b: Int, delay: Long = 0): Int {
Thread.sleep(delay)
return a + b
}
}
예제 1.7 퓨처를 사용해 작업을 실행
package future
import java.util.concurrent.Callable
import java.util.concurrent.ExecutorService
import java.util.concurrent.Executors
import java.util.concurrent.Future
fun main(args: Array<String>) {
val pool: ExecutorService = Executors.newSingleThreadExecutor()
val future: Future<*> = pool.submit(Callable {
Calculator.sum(100, 200, delay = 1000)
})
println("계산 시작")
val futureResult = future.get() // 비동기 작업의 결과를 기다린다.
println(futureResult)
val result = Calculator.sum(1, 5)
println(result)
println("계산 종료")
}
--------------------
출력 결과)
--------------------
계산 시작
300
6
계산 종료
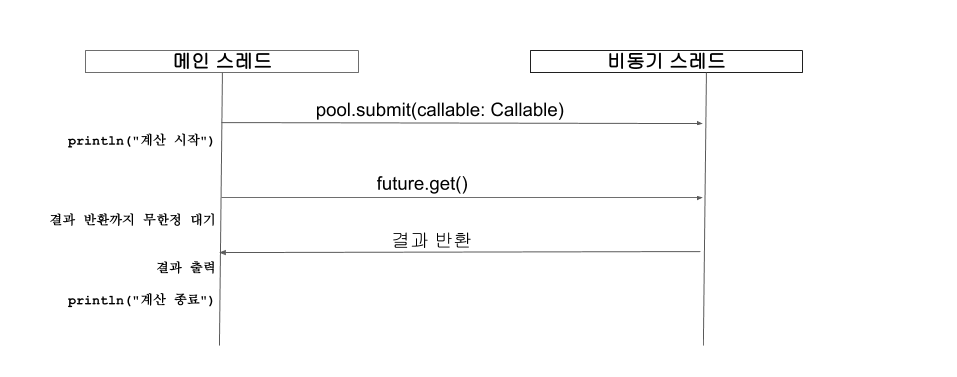
예제 1.7의 ExecutorService의 submit은 콜러블을 인자로 받아 실행합니다. 콜러블 내부에 선언된 Calculator는 sum 함수의 인자로 전달받은 delay=1000를 이용해 스레드를 1초간 일시 정지한 후 두 개 정수의 합을 계산하여 퓨처로 반환합니다. 콜러블 내부의 코드는 스레드 풀에서 전달받은 스레드를 사용해 비동기적으로 작업을 수행하게 됩니다. 비동기 작업을 수행하는 동안에 Calculator.sum(1, 5, delay = 0)의 결과는 즉시 출력되고 future.get()에서 비동기 작업에 대한 결과를 가져오게 됩니다. 이때 비동기 작업이 완료되었다면 결과를 get 함수에서 즉시 가져올 수 있지만 작업이 완료되지 않았다면 작업이 완료될 때까지 스레드는 블로킹 상태에서 결과를 기다립니다.
퓨처를 사용하면 비동기 작업을 쉽게 구현할 수 있지만 몇 가지 단점을 가지고 있습니다. 우선 퓨처를 사용하면 동시에 실행되는 한 개 이상의 비동기 작업에 대한 결과를 하나로 조합하여 처리하거나 수동으로 완료 처리(completion) 할 수 있는 방법을 지원하지 않습니다. 또한 퓨처의 get 함수는 비동기 작업의 처리가 완료될 때까지 다음 코드로 넘어가지 않고 무한정 대기하거나 지정해둔 타임아웃 시간까지 블로킹됩니다.
그림 1.4 블로킹 흐름
퓨처의 이러한 단점을 극복하기 극복하기 위해 JDK8부터 제공되는 컴플리터블 퓨처(CompletableFuture)를 사용하여 비동기 작업의 결과를 논블로킹으로 가져올 수 있는 API를 사용할 수 있습니다. 다음 예제에서는 이전에 작성했던 예제를 컴플리터블 퓨처로 변경하여 실행해보겠습니다.
예제 1.8 컴플리터블 퓨처를 사용해 작업을 실행
package future
import java.util.concurrent.*
fun main(args: Array<String>) {
val completableFuture = CompletableFuture.supplyAsync { // (1)
Calculator.sum(100, 200, delay = 2000)
}
println("계산 시작")
val futureResult = completableFuture.get() // (2)
println(futureResult)
while (!completableFuture.isDone) { // (3)
Thread.sleep(500)
println("계산 결과를 집계 중입니다.")
}
println("계산 종료")
}
--------------------
출력 결과)
--------------------
계산 시작
300
계산 종료
컴플리터블 퓨처는 퓨처와 달리 ExecutorService를 사용할 필요가 없기 때문에 컴플리터블 퓨처의 팩토리 함수인 supplyAsync를 사용해 비동기 작업을 수행했습니다. 컴플리터블 퓨처가 제공하는 supplyAsync와 같은 팩토리 함수는 명시적으로 Executor 스레드 풀을 제공하지 않으면 기본 스레드 풀로 포크-조인풀을 사용합니다.
퓨처를 사용할때와 마찬가지로 비동기 작업이 완료될때까지 블록됩니다.
isDone 속성은 말그대로 컴플리터블 퓨처가 수행 중인 비동기 작업이 완료된 상태인지를 체크합니다. 컴플리터블 퓨처는 isDone외에도 취소상태를 나타내는 isCancelled 그리고 비동기 작업 도중에 에러가 발생한 상태를 나타내는 isCompletedExceptionally도 제공합니다.
예제 1.8을 실행해보면 “계산 결과를 집계 중입니다.”라는 메시지는 출력되지 않고 계산 결과인 300이 출력된 것을 확인할 수 있습니다. 컴플리터블 퓨처를 사용해도 get 함수를 사용하면 퓨처를 사용하는 것과 동일하게 해당 라인에서 결과를 리턴할 때까지 블로킹됩니다. 컴플리터블 퓨처를 사용하는 가장 큰 이유 중 하나는 비동기 작업을 블로킹하지 않고 사용하기 위함입니다. 그러므로 thenApply 함수를 사용하면 작업이 완료될 때까지 기다리지 않고 결과를 전달받을 수 있습니다. 예제 1.9 thenApply를 사용해 논블로킹 코드로 변경
package future
import java.util.concurrent.*
fun main(args: Array<String>) {
val completableFuture = CompletableFuture.supplyAsync {
Calculator.sum(100, 200, delay = 2000)
}
println("계산 시작")
completableFuture.thenApply(::println) // 논블로킹으로 동작
while (!completableFuture.isDone) {
Thread.sleep(500)
println("계산 결과를 집계 중입니다.")
}
println("계산 종료")
}
--------------------
출력 결과)
--------------------
계산 시작
계산 결과를 집계 중입니다.
계산 결과를 집계 중입니다.
계산 결과를 집계 중입니다.
300
계산 결과를 집계 중입니다.
계산 종료
예제 1.9를 실행해보면 get을 thenApply로 변경한 후 결과가 완료되는 것을 기다리지 않고 다음 라인의 “계산 결과를 집계 중입니다.”를 출력하는 것을 확인할 수 있습니다. 이후 계산 작업이 완료 된 후 계산 결과를 출력하고 “계산 종료"를 출력한 뒤 애플리케이션이 종료됩니다.
그림 1.5 논블로킹 흐름
thenApply는 코드가 블록 되지 않기 때문에 예제 1.10과 같이 while (!completableFuture.isDone)을 주석 처리해버리면 애플리케이션은 결과를 반환하지 않고 종료됩니다.
예제 1.10 계산 결과 완료 코드 주석 처리
package future
import java.util.concurrent.*
fun main(args: Array<String>) {
val completableFuture = CompletableFuture.supplyAsync {
Calculator.sum(100, 200, delay = 2000)
}
println("계산 시작")
completableFuture.thenApply(::println) // 논블로킹으로 동작
// while (!completableFuture.isDone) {
// Thread.sleep(500)
// println("계산 결과를 집계 중입니다.")
// }
println("계산 종료")
}
--------------------
출력 결과)
--------------------
계산 시작
계산 종료
예상대로 계산 결과는 출력되지 않고 바로 종료된것을 확인 할 수 있습니다. 논블로킹으로 동작하는 코드를 작성할때는 이러한 특징에 대해 이해하고 개발하지 않으면 의도치 않은 버그를 만들 수 있다는 단점이 있습니다. 이번엔 컴플리터블 퓨처를 활용해 다수의 작업을 병렬로 처리하는 예제에 대해 알아보겠습니다. 예제 1.11에선 의도대로 병렬 처리가 되는지 또한 얼마나 시간이 소요되는지 확인하기 위해 소요 시간을 측정하는 코드를 추가하였습니다.
예제 1.11 계산 소요 시간 측정
val startTime = System.nanoTime()
println("계산 시작")
println("계산 종료")
val elapsedTime = (System.nanoTime() - startTime) / 1_000_000
println("수행시간 : $elapsedTime msecs")
다음 예제는 비동기 작업을 5번 반복하면서 결과를 출력하는 코드입니다.
예제 1.12 병렬 처리 구현1
package future
import java.util.concurrent.*
fun main(args: Array<String>) {
val startTime = System.nanoTime()
println("계산 시작")
(0 until 5).forEach {
val supplier = {
println("current-thread-name:${Thread.currentThread().name}")
Calculator.sum(100, 200, delay = 2000)
}
val result = CompletableFuture.supplyAsync(supplier).join()
println(result)
}
println("계산 종료")
val elapsedTime = (System.nanoTime() - startTime) / 1_000_000
println("수행시간 : $elapsedTime msecs")
}
--------------------
출력 결과)
--------------------
계산 시작
current-thread-name : ForkJoinPool.commonPool-worker-9
300
current-thread-name : ForkJoinPool.commonPool-worker-9
300
current-thread-name : ForkJoinPool.commonPool-worker-9
300
current-thread-name : ForkJoinPool.commonPool-worker-9
300
current-thread-name : ForkJoinPool.commonPool-worker-9
300
계산 종료
수행시간 : 10021 msecs
우선 (0 until 5).forEach 내부에서 이전 예제와 동일하게 비동기 계산 로직을 추가하고 join을 사용해 결과를 받아온 뒤 출력합니다. 이번에 사용한 join은 get과 동일하게 비동기 작업의 결과를 받아옵니다. 하지만 get은 익셉션이 발생하면 throw를 사용해 익셉션을 외부로 전파해서 try-catch 구문으로 예외 처리를 해야 하는데 반해 join은 익셉션을 외부로 전파시키지 않는다는 차이점이 있습니다. 예제 1.12의 실행 결과는 예상과 다르게 10초가 소요되었고 current-thread-name에 5번 모두 동일한 스레드가 찍힌 것을 확인할 수 있습니다. 그러므로 작성한 예제가 병렬로 처리되지 않고 순차 처리되었단 걸 알 수 있습니다. 이런 결과가 발생한 이유는 join 역시 get과 마찬가지로 작업의 결과를 가져올때 블로킹되는데 join을 반복문 내부에서 수행했기 때문에 의도와는 다르게 순차적으로 처리되었습니다. 이제 이유를 알았으니 예제를 개선해보겠습니다.
예제 1.13 병렬 처리 구현2
package future
import java.util.concurrent.*
fun main(args: Array<String>) {
val startTime = System.nanoTime()
println("계산 시작")
(0 until 5).map {
val supplier = {
println("current-thread-name:${Thread.currentThread().name}")
Calculator.sum(100, 200, delay = 2000)
}
CompletableFuture.supplyAsync(supplier)
}.map(CompletableFuture<Int>::join).forEach(::println)
println("계산 종료")
val elapsedTime = (System.nanoTime() - startTime) / 1_000_000
println("수행시간 : $elapsedTime msecs")
}
--------------------
출력 결과)
--------------------
계산 시작
current-thread-name : ForkJoinPool.commonPool-worker-9
current-thread-name : ForkJoinPool.commonPool-worker-2
current-thread-name : ForkJoinPool.commonPool-worker-11
current-thread-name : ForkJoinPool.commonPool-worker-4
current-thread-name : ForkJoinPool.commonPool-worker-6
300
300
300
300
300
계산 종료
수행시간 : 2034 msecs
마지막으로 개선한 예제 1.13에선 map 함수를 사용해서 5개의 CompletableFuture<Int>를 가지는 리스트로 변환하고 그다음 map에선 join으로 가져온 결과를 모아서 List<Int>로 변환하였습니다. 그리고 마지막 forEach에선 전달받은 정수형 리스트를 가지고 println을 출력하도록 수정했습니다. 예제의 실행 결과를 보면 의도대로 각기 다른 스레드가 계산 작업을 병렬로 나눠 처리한 것을 확인할 수 있습니다. 또한 기존 코드 보다 약 5배 빠른 2초 만에 처리가 완료되었습니다. 이처럼 컴플리터블 퓨처를 사용하면 논블로킹으로 동작하거나 수행 결과를 조합하는 코드도 어렵지 않게 구현할 수 있습니다.
이번 장에선 다양한 방법을 사용해 비동기 프로그래밍을 구현해봤습니다. 특히 컴플리터블 퓨처는 기존의 비동기 처리 방법에 비해 우아하고 편리합니다. 컴플리터블 퓨처가 만능 해결사는 아니지만 대다수의 비동기 처리 시나리오에서 유용하게 사용할 수 있습니다. 예를 들면 우리가 개발한 서버에서 외부의 여러 API 서버를 호출하여 응답을 받아서 결과를 결합하고 처리해야 하는 시나리오라면 컴플리터블 퓨처는 매우 유용할 것입니다.
그림 1.6 컴플리터블 퓨처가 잘 사용된 시나리오
하나의 컴플리터블 퓨처는 단순히 한 번의 비동기 작업을 정의하고 처리합니다. 반면에 리액티브 프로그래밍은 데이터의 크기가 정해지지 않고 지속적으로 생성되는 데이터를 처리하는 스트리밍 형태로써 데이터 전달의 주체인 발행자는 데이터가 준비되면 데이터를 구독자에게 통지하고 구독자는 자신이 처리할 수 있는 만큼의 데이터를 처리합니다. 이런 처리 방법은 일반적인 비동기 프로그래밍으로는 처리하기 힘들고 구현도 쉽지 않습니다. 이때 리액티브 프로그래밍을 적용하면 최소한의 노력으로 복잡한 비동기 작업을 핸들링 할 수 있습니다.
리액티브 프로그래밍(Reactive Programming)이란 데이터 또는 이벤트의 변경이 발생하면 이에 반응해 처리하는 프로그래밍 기법을 말합니다. 리액티브 프로그래밍은 2010년 에릭 마이어라는 프로그래머에 의해 마이크로소프트의 .NET 에코 시스템으로 정의되었습니다. 리액티브 프로그래밍의 특징은 비동기 프로그래밍을 처리하는 새로운 접근 방식이라는 것입니다. 리액티브 프로그래밍은 데이터의 통지, 완료, 에러에 대한 처리를 옵저버 패턴에 영감을 받아 설계되었고 데이터의 손쉬운 비동기 처리를 위해 함수형 언어의 접근 방식을 사용합니다.
리액티브 프로그래밍이 나오기 전 비동기 프로그래밍은 대부분 콜백(Callback)기반의 비동기 처리 방식을 사용했습니다. 간단한 비동기 처리는 콜백 기반의 비동기 프로그래밍으로도 이해하기 쉬운 코드를 작성할 수 있지만 콜백이 많아져서 발생하는 일명 콜백 헬(Callback Hell)로 인해 코드의 복잡도가 늘어나서 가독성과 유지 보수성이 떨어지게 됩니다. 그동안 콜백 헬을 해결하기 위해 다양한 해결 방법들이 제시되었고 리액티브 프로그래밍을 적용하면 콜백 헬 없이 읽기 쉬운 코드를 작성할 수 있기 때문에 서버 애플리케이션 관점에서 리액티브 프로그래밍은 비동기 기반의 논-블로킹(Non-Blocking)과 이벤트 드리븐(Event-Driven) 애플리케이션 구현에 유리하여 최근 리액티브 프로그래밍을 적용한 사례가 점점 늘어나고 있습니다. 리액티브 프로그래밍은 비동기 처리 외에도 백프레셔(Back-Pressure)이라는 특징을 포함합니다. 백프레셔는 데이터를 소비하는 측에서 처리 가능한 만큼의 양을 데이터 제공자 측에 역으로 요청하는 기능입니다. 데이터 제공자와 데이터 소비자가 다른 스레드에서 비동기로 처리될 경우 주로 사용되며 제공자 측에서 너무 빠르게 데이터를 제공하면 소비하는 측에선 빠르게 처리하지 못해서 데이터가 점점 쌓이면 시스템에 장애 요소가 될 수 있는데 백프레셔는 이런 문제를 해결할 수 있습니다.
리액티브 프로그래밍과 디자인 패턴
리액티브 프로그래밍을 설명할 때 빠지지 않고 등장하는 디자인 패턴이 옵저버 패턴(Observer Pattern)과 이터레이터 패턴(Iterator Pattern)입니다. 리액티브 프로그래밍은 옵저버 패턴 그리고 이터레이터 패턴과 자주 비교되며 또한 영감을 받은 걸로 알려져 있습니다. 이번 절에 선 두 개의 패턴과 리액티브 프로그래밍 간에 어떤 차이점이 있는지 알아보겠습니다.
옵저버 패턴
옵저버 패턴이란 GoF가 소개한 디자인 패턴 중 하나로 관찰 대상이 되는 객체가 변경되면 대상 객체를 관찰하고 있는 옵저버(Observer)에게 변경사항을 통지(notify) 하는 디자인 패턴을 말합니다. 옵저버 패턴을 사용하면 객체 간의 상호작용을 쉽게 하고 효과적으로 데이터를 전달할 수 있습니다. 옵저버 패턴은 관찰 대상인 서브젝트(Subject)와 서브젝트를 관찰하는 옵저버로 이뤄져 있습니다. 하나의 서브젝트에는 하나 또는 여러 개의 옵저버를 등록할 수 있고 상태가 변경되면 자신을 관찰하는 옵저버들에게 변경 사항을 통지합니다. 서브젝트로부터 통지를 받은 옵저버는 부가적인 처리를 합니다.
그림 1.1 옵저버 패턴의 구조
일반적으로 옵저버 패턴은 서브젝트와 옵저버를 상속하는 구체화(concrete) 클래스가 있습니다. 구체화 클래스는 서브젝트와 옵저버의 시그니처에 대한 상세 구현을 작성합니다. 구체화 클래스를 작성하기 위해 알아야 할 서브젝트와 옵저버의 필수 함수를 살펴보겠습니다.
표 1.1 서브젝트의 함수
함수
설명
add
서브젝트의 상태를 관찰할 옵저버 등록한다.
remove
등록된 옵저버를 삭제한다.
notify
서브젝트 상태가 변경되면 등록된 옵저버에 통지한다.
표 1.2 옵저버의 함수
함수
설명
update
서브젝트의 notify 내부에서 호출되며 서브젝트의 변경에 따른 부가 기능을 처리
옵저버 패턴에 대해 간략히 알아봤으니 이번엔 JDK는 1.0 부터 포함된 Observable 클래스와 Observer 인터페이스를 사용해 간단한 커피 주문 예제를 만들어 보겠습니다. Observable은 옵저버 패턴의 서브젝트와 동일합니다.
예제 1.1 옵저버 패턴으로 구현한 커피 주문 예제
import java.util.*
class Customer : Observer {
fun orderCoffee() = "Iced Americano"
override fun update(o: Observable?, arg: Any?) {
val coffee = arg as Coffee
println("I got a cup of ${coffee.name}")
}
}
class Coffee(val name: String)
class Barista : Observable() {
private fun makeCoffee(name: String) = Coffee(name)
fun serve(name: String) {
setChanged()
notifyObservers(makeCoffee(name))
}
}
fun main(args: Array<String>) {
val barista = Barista()
val customer = Customer()
barista.addObserver(customer)
barista.serve(customer.orderCoffee())
}
--------------------
출력 결과)
--------------------
I got a cup of Iced Americano
Customer 클래스는 Observer 인터페이스를 구현하여 Barista 클래스가 커피를 완성하면 통지를 받아서 update 함수에서 처리한다.
Barista 클래스는 Observable 클래스를 상속하여 고객이 주문한 커피가 만들어지면 notifyObservers로 고객에게 만들어진 Coffee 객체를 전달한다. 이때 setChanged를 먼저 호출하여 변경 여부를 내부에 저장한다.
Customer 클래스가 Barista 클래스를 관찰하기 위해 addObserver로 등록한다.
예제 1.1과 같이 옵저버 패턴을 사용하지 않았다면 고객은 일정 간격으로 커피가 완성됐는지 바리스타에게 확인하는 처리가 있어야 합니다. 간격이 너무 짧으면 변경된 상태를 빠르게 확인할 수 있지만 매번 불필요한 호출이 발생하므로 성능상 문제가 발생할 수 있습니다. 또 간격이 너무 길면 변경된 상태를 즉시 확인할 수 없으므로 실시간성이 떨어질 수 있습니다. 옵저버 패턴은 관찰자인 옵저버가 서브젝트의 변화를 신경 쓰지 않고 상태 변경의 주체인 서브젝트가 변경사항을 옵저버에게 알려줌으로써 앞서 언급한 문제를 해결할 수 있습니다. 옵저버 패턴에서 서브젝트와 옵저버는 관심사에 따라 역할과 책임이 분리되어 있습니다. 서브젝트는 옵저버가 어떤 작업을 하는지 옵저버의 상태가 어떤지에 대해 관심을 가질 필요가 없습니다. 오직 변경 사항을 통지하는 역할만 수행하고 하나 혹은 다수의 옵저버는 각각 맡은 작업을 스스로 하기 때문에 옵저버가 하는 일이 서브젝트에 영향을 끼치지 않고 옵저버는 단순한 데이터의 소비자로서 존재하게 됩니다. 리액티브 프로그래밍은 옵저버 패턴의 서브젝트와 옵저버의 개념과 유사한 발행자와 구독자를 사용해 데이터를 통지하고 처리합니다. 데이터를 제공하는 측에서 데이터를 소비하는 측에 통지하는 방식을 일반적으로 푸시 기반(Push-Based)이라고 부릅니다.리액티브 프로그래밍은 옵저버 패턴의 단순한 데이터 통지 기능에 더해서 백프레셔라는 특징을 통해 데이터를 처리하는 측에서 데이터를 전달받는 개수를 역으로 요청할 수 있습니다. 그러므로 데이터를 통지하는 주체의 통지 속도를 제어하고 처리하는 측에서는 자신이 처리 가능한 만큼의 데이터만 받아서 처리할 수 있게 됩니다.
이터레이터 패턴
이터레이터 패턴은 옵저버 패턴과 마찬가지로 GoF가 소개한 디자인 패턴 중 한 가지입니다. 이터레이터 패턴은 데이터의 집합에서 원소라고 불리는 데이터를 순차적으로 꺼내기 위해 만들어진 디자인 패턴입니다. 이터레이터 패턴을 사용하면 다른 컬렉션을 사용해도 동일한 인터페이스를 사용해 데이터를 꺼내올 수 있기 때문에 컬렉션이 변경되더라도 사용하는 쪽에서는 변경사항이 발생하지 않습니다. 이러한 장점 때문에 이터레이터 패턴을 사용하면 코드를 좀 더 유연하고 확장성 있게 만듭니다.
그림 1.2 이터레이터 패턴의 구조
그림 1.2의 에그리게잇(Aggregate)은 자료구조의 리스트, 맵, 세트와 같은 구조가 집합체에 해당합니다. 이터레이터(Iterator)는 집합체 내부에 구현된 iterator를 이용해 생성합니다. 클라이언트는 생성된 이터레이터를 사용해 hasNext 함수에서 내부에 데이터가 존재하는지를 확인하고 next 함수를 사용해 데이터를 꺼내옵니다.
표 1.3 에그리게잇의 함수
함수
설명
iterator
이터레이터를 생성한다.
표 1.4 이터레이터의 함수
함수
설명
hasNext
데이터가 존재하는지를 판단하여 true 또는 false를 반환한다.
next
데이터가 존재한다면 데이터를 꺼내온다.
이번에는 코틀린 컬렉션 라이브러리에 포함된 Iterable과 Iterator를 사용해 간단한 이터레이터 패턴을 구현해 보겠습니다.
예제 1.2 이터레이터 패턴 예제
package iterator
data class Car(val brand: String)
class Cars(val cars: List<Car> = listOf()) : Iterable<Car> {
override fun iterator() = CarsIterator(cars)
}
class CarsIterator(val cars: List<Car> = listOf(), var index: Int = 0) : Iterator<Car> {
override fun hasNext() = cars.size > index
override fun next() = cars[index++]
}
fun main(args: Array<String>) {
val cars = Cars(listOf(Car("Lamborghini"), Car("Ferrari")))
val iterator = cars.iterator()
while (iterator.hasNext()) {
println("brand : ${iterator.next()}")
}
}
--------------------
출력 결과)
--------------------
brand : Car(brand=Lamborghini)
brand : Car(brand=Ferrari)
Cars 클래스는 Iterable 인터페이스를 구현하여 CarsIterator를 리턴하는 iterator 함수를 오버라이드 한다.
CarsIterator 클래스는 Iterator 인터페이스를 구현하여 데이터가 존재하는지 확인하는 hasNext와 데이터가 존재하면 데이터를 가져오는 next 함수를 오버라이드 한다.
while문 내부에선 hasNext를 사용하여 데이터를 모두 가져올때까지 반복하고 데이터를 출력한다.
데이터를 제공한다는 관점에서 이터레이터 패턴과 리액티브 프로그래밍은 유사하지만 이터레이터 패턴은 에그리게잇이 내부에 데이터를 저장하고 이터레이터를 사용해 데이터를 순차적으로 당겨오는 방식이기 때문에 풀 기반(Pull-Based)입니다. 이에 반해 리액티브 프로그래밍은 기본적으로 옵저버 패턴 처럼 데이터 제공자가 소비하는 측에 데이터를 통지하는 푸시 기반이기 때문에 분명한 차이점이 있습니다. 다만 구현체의 사양에 따라서 풀과 푸시를 모두 제공하는 경우도 있습니다.
분명 ConnectionPoolConfiguration에 initialSize와 maxSize를 넣었는데 비정상적으로 동작하는 것을 확인.
to-be
option(DRIVER, "pool")을 추가하였음. 이 설정은 추가하는 이유는 github.com/r2dbc/r2dbc-pool를 보면 Supported ConnectionFactory Discovery Options섹션에 아래와 같이 무조건 pool(Must be pool)로 설정하라고 되어 있음